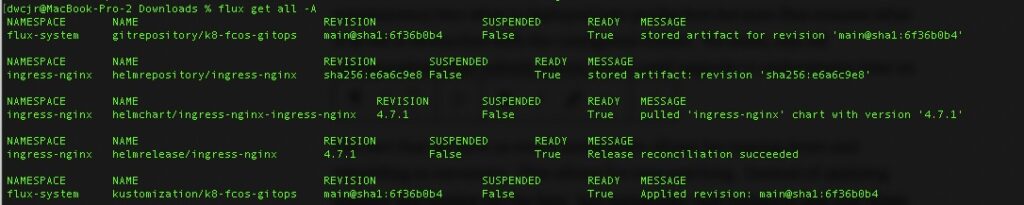
Building on the prior article of Fedora CoreOS + Ansible => K8s we want complete Infrastructure As Code. The newest way of doing this is GitOps where nearly everything is controlled by SCM. For that, flux is one of my favorites but Argo will also work.
The benefit of GitOps and K8s is that developers can have complete but indirect access to various environments. This makes it really easy for a DevOps team to provision the tooling very easily to either spin up environments effortlessly or let the developers do it themselves. That helps us get close to Platform Engineering.
Flux GitOps Repo
For this article, this is the tagged version of the GitOps repo used. At its core, we manually generated the yaml manifests via scripts commands. Namely upgrade_cluster1.sh and generate_cluster1.sh. Combined these create the yaml manifests needed. Upgrade cluster can be run to refresh the yaml during an upgrade but do not let it trick you. It can also be used to generate the initial component yaml. The generate_cluster1.sh should only need to be run once.
The flux cli has a bootstrap command that can be used but for this, we want disposable K8s clusters that can be torn down and then new ones rebuilt and attached to the same repo. Not only does this allow the workloads running to be treated like cattle but also the infrastructure itself.
To achieve this, we are manually creating the yaml manifests (still using the supported CLI tools) but decoupling that from the initial setup, deploy and running of the environment.
What Did We Get?
From a simple set of changes to pull and deploy flux, we have a sample ingress controller (nginx). In it you can specify any parameter about it and have clear visibility as to what is deployed. In this scenario we are just specifying the version but we could also specify how many instances or whether to deploy via daemonset (one instance per worker node).
Wrapping It All Up – What Is The Big Deal?
It might be a natural question as to what is the big deal about K8s, IaC, GitOps and this entire ecosystem. True IaC combined with GitOps allows complete transparency into what is deployed into production because flux ensures what is in Git is reconciled with the configured cluster. No more, one off configurations that nobody knows about until upgrade to replacement time on the server.
The fact that we have so much automation allows for tearing down and rebuilding as necessary. This allows for easy patching. Instead of applying updates and hoping for the best, just instantiate new instances and tear down the old ones.
SaltStack or Salt for short is an open source configuration management platform. It was first released in the early 2010’s as a potential replacement for Chef and Puppet. In this guide we will walk through some high level details of Salt and a basic install. If you already have Salt installed, please skip ahead to the next article when it is published.
A configuration management tool allows you to remotely configure and dictate configurations of machines. Through this multi-part series we will work through that with the use case of https://blog.woohoosvcs.com/. At some point this site may need multiple front ends. It has not been decided if that method will be Kubernetes, Google App Engine or VMs. If the VM route is chosen it will make sense to have an easy template to use.
What Configuration Management is not
Configuration management typically does not involve the original provisioning of the server. There are typically other tools for that such as Terraform.
Salt Architecture
Salt has three main components to achieve configuration management. Those are the salt master, minion and client. Salt can be configured highly available with multi master but it is not necessary to start out there. For the sake of this document and per Salt’s best practices we can add that later if necessary. – https://docs.saltstack.com/en/latest/topics/development/architecture.html
Salt Client
The salt client is a command line client that accepts commands to be issued to the salt master. It is typically on the salt master. You can use it to trigger expected states.
Salt Master
The Salt Master is the broker of all configuration management and the brains. Requests/commands received from the client make their way to the master which then get pushed to the minion.
Salt Minion
The minion is typically loaded onto each machine you wish to perform configuration management on. In our case, it will be the new front ends we spin up as we need them.
Firewall Ports
The Salt Master needs ports TCP/4505-4506 opened. The minions check in and connect to the master on those ports. No ports are needed for the minions as they do not listen on ports.
Typically you want the master to be well connected since the minions will be connecting to it. Even if you are primarily on prem, it is not a bad idea to put a salt master in the cloud.
For the installation we will be closely following Salt’s documentation on installing for RHEL 8 – https://repo.saltstack.com/#rhel
For the sake of this lab we will have the client, master and minion all on the same server but it will allow us to build out the topology.
Now to the install!
# I always like to start out with the latest up to date OS
sudo yum update
# Install the salt repo for RHEL/CentOS
sudo yum install https://repo.saltstack.com/py3/redhat/salt-py3-repo-latest.el8.noarch.rpm
# Install minion and master
sudo yum install salt-master salt-minion
# Reboot for OS updates to take effect
reboot
On the minion we need to edit “/etc/salt/minion”. The following changes need to be made. If/when you roll this out into production you can use DNS hostnames.
#master: salt
master: 192.168.116.186
We will also open up the firewall ports on the master
Wait about 5 minutes. It takes a little bit to initialize. Once it has you can run “sudo salt-key -L”. When a minion connects to the master, the master does not allow it to connect automatically. It has to be permitted/admitted. salt-key can be used to list minions and allow them.
$ sudo salt-key -L
Accepted Keys:
Denied Keys:
Unaccepted Keys:
saltmaster1.woohoosvcs.com
Rejected Keys:
$ sudo salt-key -A
The following keys are going to be accepted:
Unaccepted Keys:
saltmaster1.woohoosvcs.com
Proceed? [n/Y] Y
Key for minion saltmaster1.woohoosvcs.com accepted.
[dwcjr@saltmaster1 ~]$ sudo salt-key -L
Accepted Keys:
saltmaster1.woohoosvcs.com
Denied Keys:
Unaccepted Keys:
Rejected Keys:
We used salt-key -A to accept all unaccepted keys.
Testing
$ sudo salt saltmaster1 test.version
[WARNING ] /usr/lib/python3.6/site-packages/salt/transport/zeromq.py:42: VisibleDeprecationWarning: zmq.eventloop.minitornado is deprecated in pyzmq 14.0 and will be removed.
Install tornado itself to use zmq with the tornado IOLoop.
import zmq.eventloop.ioloop
No minions matched the target. No command was sent, no jid was assigned.
ERROR: No return received
[root@saltmaster1 ~]# salt '*' test.version
[WARNING ] /usr/lib/python3.6/site-packages/salt/transport/zeromq.py:42: VisibleDeprecationWarning: zmq.eventloop.minitornado is deprecated in pyzmq 14.0 and will be removed.
Install tornado itself to use zmq with the tornado IOLoop.
import zmq.eventloop.ioloop
saltmaster1.woohoosvcs.com:
2019.2.2
Well that is an ugly error code. It seems to have been introduced in 2019.2.1 but not properly fixed in 2019.2.2. My guess is the next release will fix this but it seems harmless. – https://github.com/saltstack/salt/issues/54759. We do, however, get the response so this is a success.
Final Words
At this point we have a salt-master and salt-minion setup, albeit on the same host. We have accepted the minion on the master and they are communicating. The next article will start to tackle setting up Salt states and other parts of the salt configuration.
The Rancher ecosystem is an umbrella of tools. We will specifically be talking about the Rancher product or sometimes referred to as Rancher Server. Rancher is an excellent tool for managing and monitoring your Kubernetes cluster, no matter where it exists.
Requirements and Setup
The base requirement is just a machine that has docker. For the sake of this article, we will use their RancherOS to deploy.
RancherOS touts itself at being the lightest weight OS capable of running docker. All of the system services have been containerized as well. The most difficult part of installing “ros” is using the cloud-init.yaml to push your keys to it!
We will need the installation media as can be found here
The minimum requirements state 1GB of RAM but I had issues with that and bumped my VM up to 1.5GB. It was also provisioned with 1 CPU Core and 4GB HDD.
A cloud-config.yml should be provisioned with your ssh public key
We also assume you will be picking up from the Intro to Kubernetes article and importing that cluster.
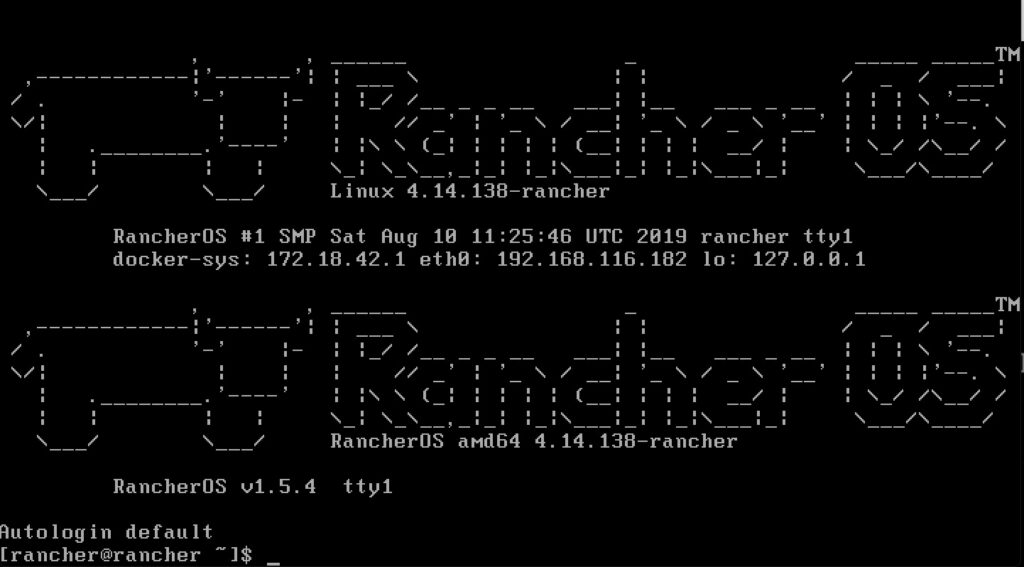
Installing RacherOS
Autologin prompt on rancheros
On my laptop I ran the following command in the same directory that I have the cloud-config.yml. This is a neat way to have a quick and dirty web server on your machine.
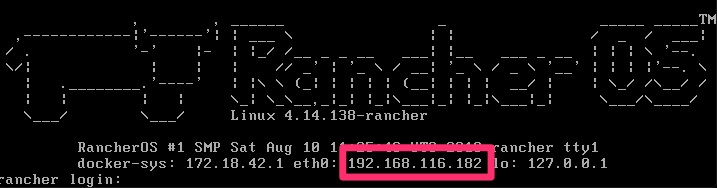
A few prompts including a reboot and you will be asking yourself if it was just that easy? When it boots up, it shows you the IP to make it that much easier to remotely connect. Afterall, you are only enabled for ssh key auth at this point and cannot really login at the console.
Rancher Second Boot
% ssh [email protected]
The authenticity of host '192.168.116.182 (192.168.116.182)' can't be established.
ECDSA key fingerprint is SHA256:KGTRt8HZu1P4VFp54vOAxf89iCFZ3jgtmdH8Zz1nPOA.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.116.182' (ECDSA) to the list of known hosts.
Enter passphrase for key '/Users/dwcjr/.ssh/id_rsa':
[rancher@rancher ~]$
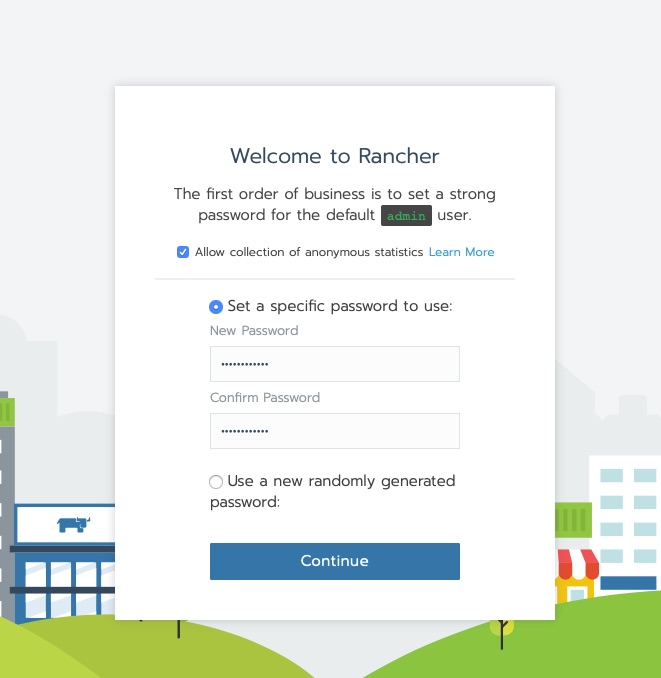
Connect via HTTPS to the rancher server and you’ll get the new user creation for admin
Welcome to Rancher!
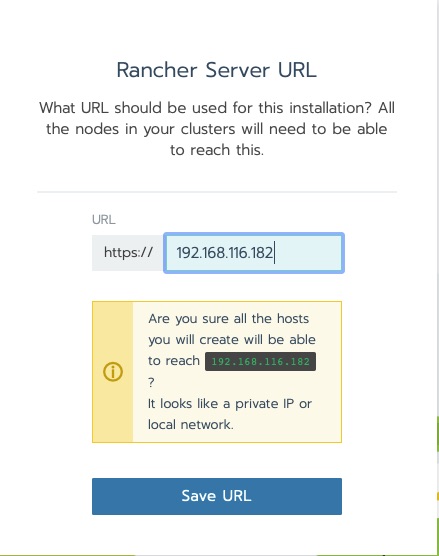
The next question is an important design decision. The Kubernetes nodes that this will be managing need to be able to connect to the rancher host. the reason being is agents are deployed that phone home. The warning in this next message is ok for this lab.
Rancher Server URL
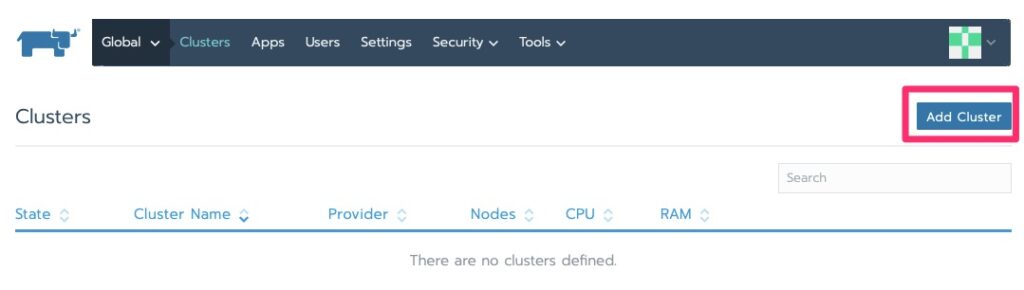
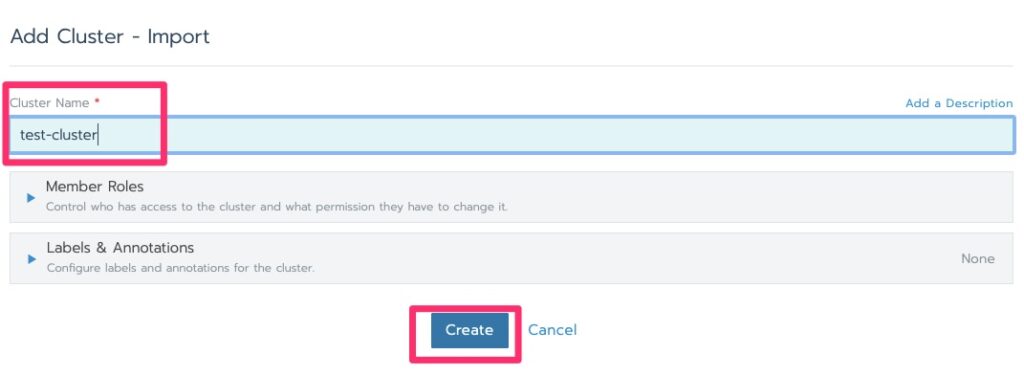
Importing a Cluster
Add ClusterImport Existing Cluster
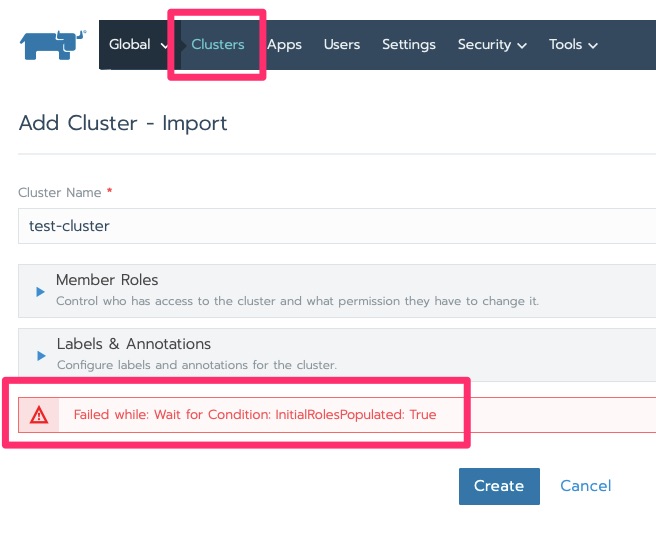
In this lab I have been getting the following error but click over to clusters and it moves on with initializing.
Failed while: Wait for Condition: InitialRolesPopulated: True
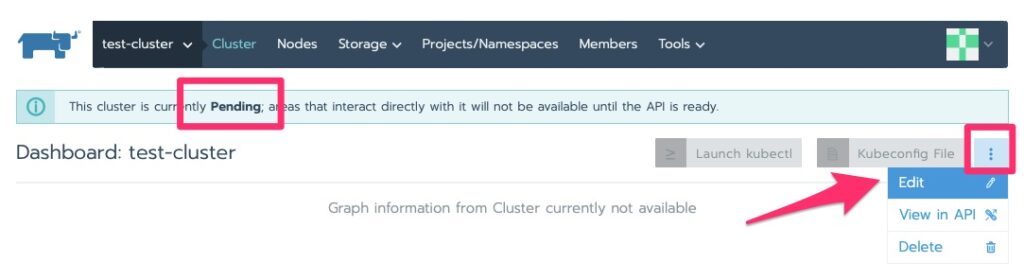
It will stay in initializing for a little bit. Particularly in this lab with minimal resources. We are waiting for “Pending”.
Now that it is pending we can edit it for the kubectl command to run on the nodes to deploy the agent
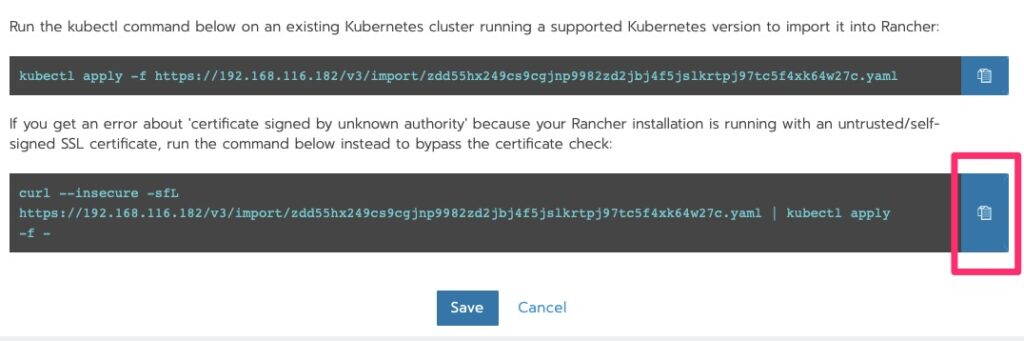
Pending is good. Now we want to edit.Copy the bottom option to the clipboard since we used a self-signed cert that the Kubernetes cluster does not trust.
Deploying the Agent
Run the curl!
root@kube-master [ ~ ]# curl --insecure -sfL https://192.168.116.182/v3/import/zdd55hx249cs9cgjnp9982zd2jbj4f5jslkrtpj97tc5f4xk64w27c.yaml | kubectl apply -f -
clusterrole.rbac.authorization.k8s.io/proxy-clusterrole-kubeapiserver created
clusterrolebinding.rbac.authorization.k8s.io/proxy-role-binding-kubernetes-master created
namespace/cattle-system created
serviceaccount/cattle created
clusterrolebinding.rbac.authorization.k8s.io/cattle-admin-binding created
secret/cattle-credentials-79f50bc created
clusterrole.rbac.authorization.k8s.io/cattle-admin created
deployment.apps/cattle-cluster-agent created
The DaemonSet "cattle-node-agent" is invalid: spec.template.spec.containers[0].securityContext.privileged: Forbidden: disallowed by cluster policy
Boo – what is “disallowed by cluster policy”? This is a permission issue
On Kubernetes 1.14 you can set “–allow-privileged=true” on the apiserver and kubelet. It is deprecated in higher versions. Make that change on our 1.14 cluster and we’re off to the races!
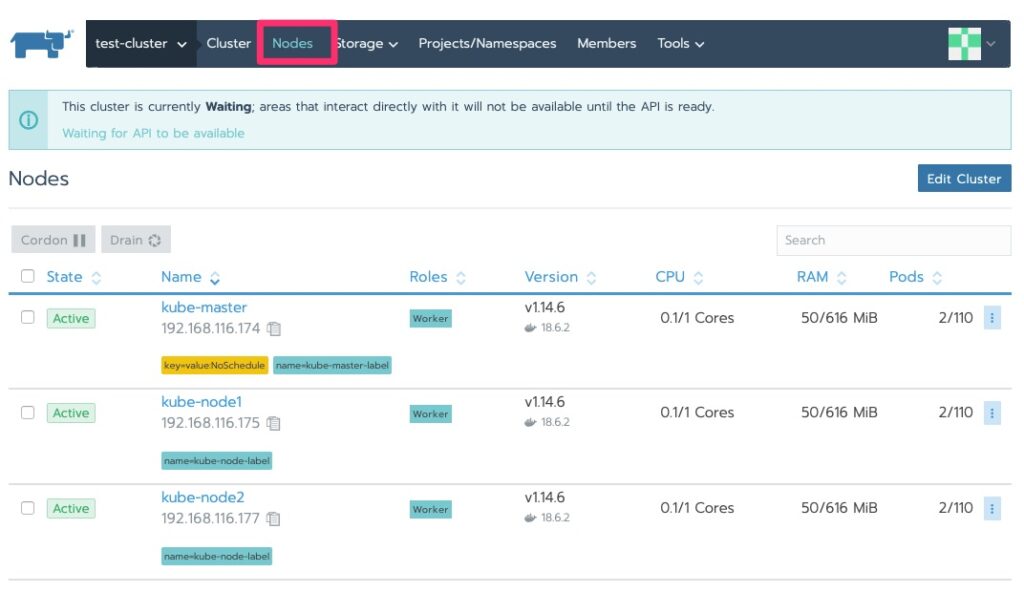
Slow races but we’re off. Give it a good few minutes to make some progress. While we wait for this node to provision, set the “–allow-privileged=true” on the other nodes in /etc/kubernetes/kubelet
We should now see some nodes and the status has changed to “waiting” and we will do just that. By now, if you haven’t realized, Kubernetes is not “fast” on the provisioning. Well at least in these labs with minimal resources 🙂
Cluster Status Waiting and nodes exist.
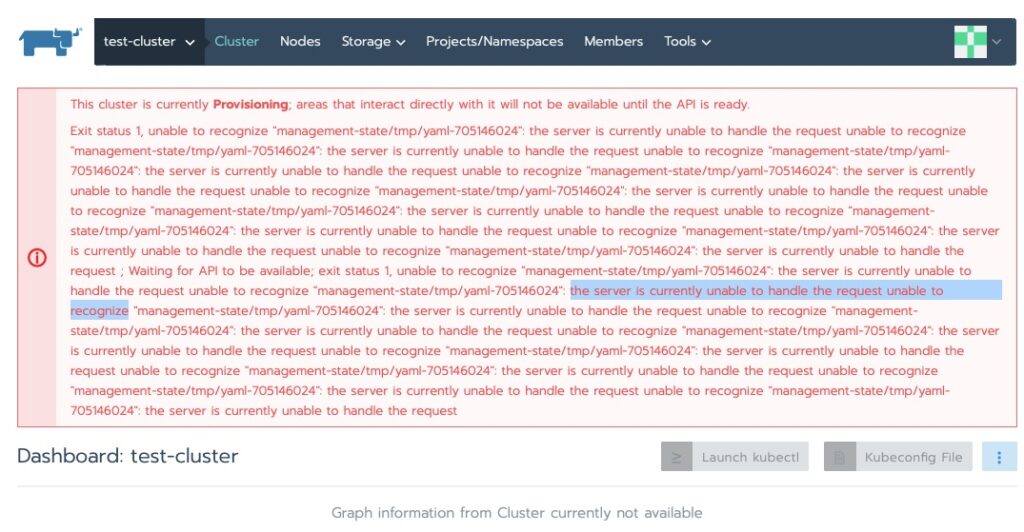
Checking on the status I ran into this. My first thought was RAM on the master node. I have run into this enough before.
This cluster is currently Provisioning; areas that interact directly with it will not be available until the API is ready. Exit status 1, unable to recognize “management-state/tmp/yaml-705146024”: the server is currently unable to handle the request unable to recognize “management-state/tmp/yaml-705146024”
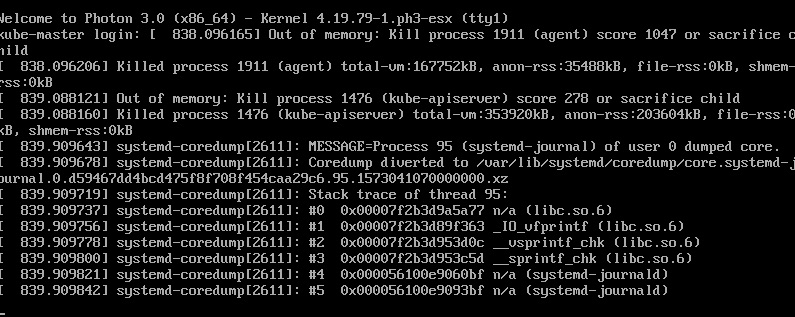
Sure enough, running top and checking the console confirmed that.
kube-master out of ram. Time to increase a little to cover the overhead of the agent. Went from 768MB to 1024MB and back up and at ’em!
It did sit at the following error for some time.
This cluster is currently Provisioning; areas that interact directly with it will not be available until the API is ready.
Exit status 1, unable to recognize "management-statefile_path_redacted":
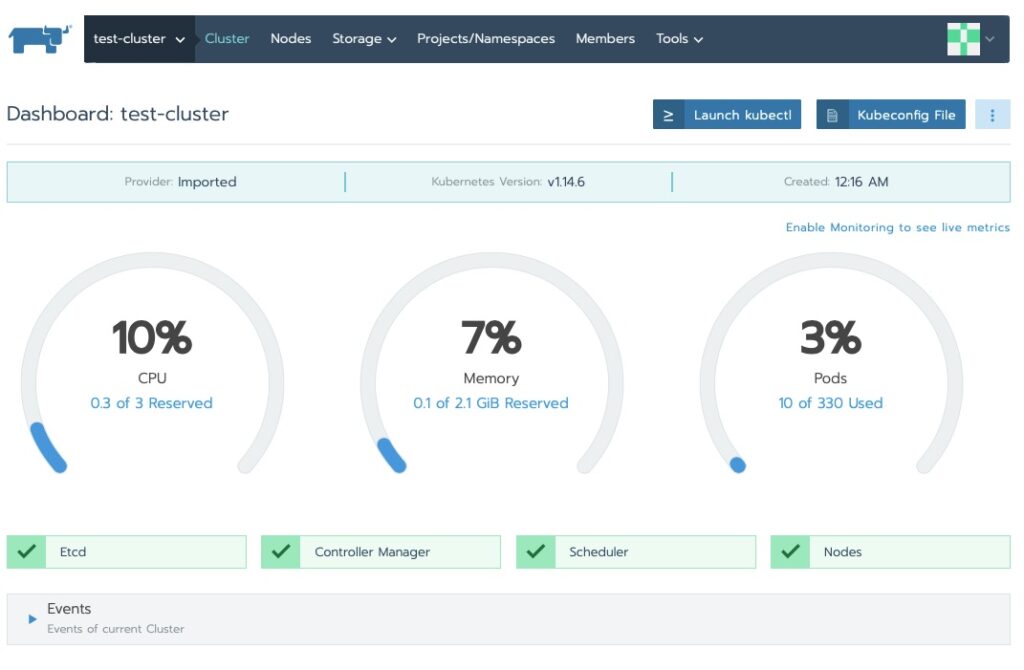
Some indications show this eventually resolves itself. Others have indicated adding a node helps kick off the provisioning to continue. In my case a good 10 minutes and we’re all green now!
Rancher Cluster Dashboard
Navigating Around
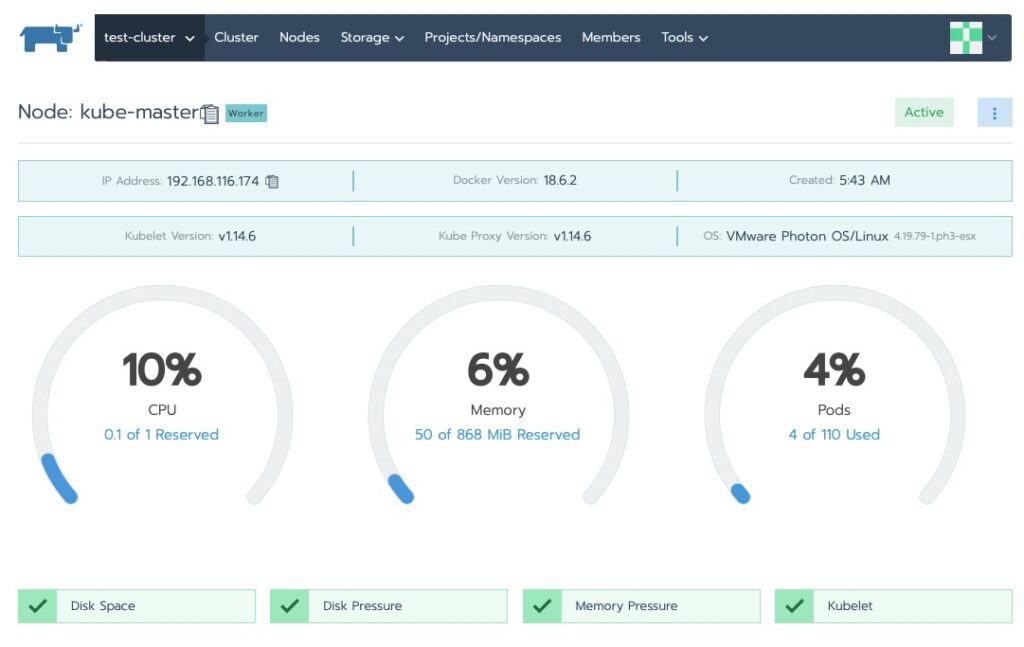
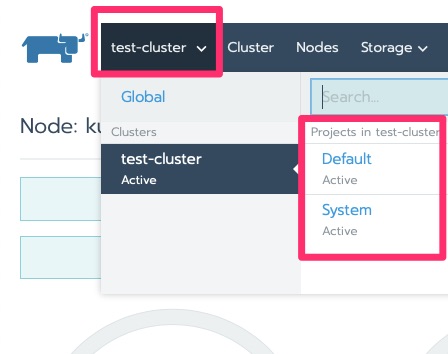
We saw the cluster area. Let’s drill into the nodes!
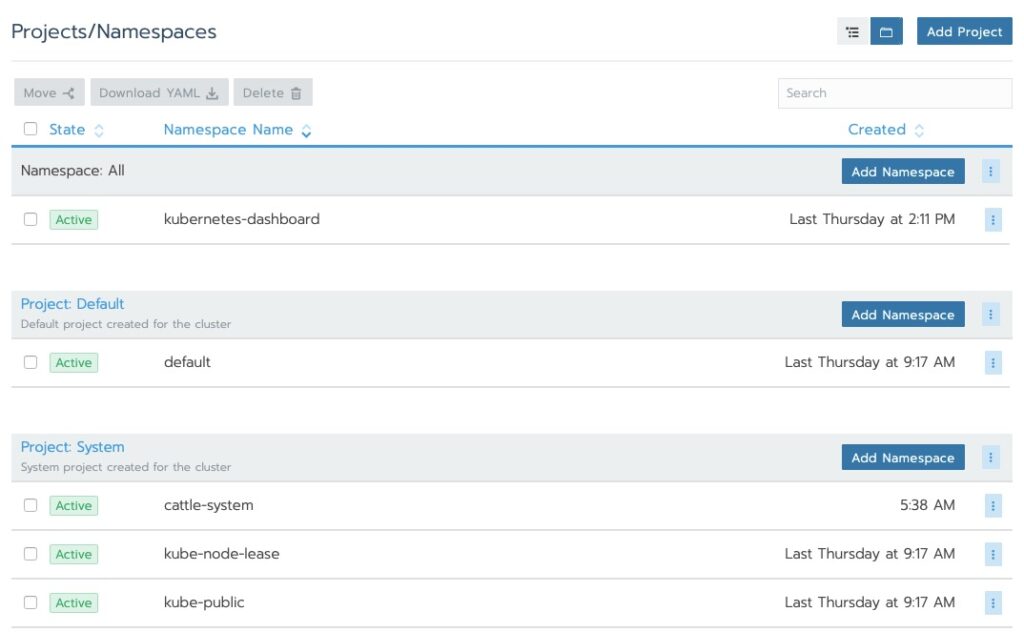
Rancher Dashboard NodesRancher partitions the clusters into System and Default. This is a carryover from “ros” which does the same to the OS.Rancher Projects and Namespaces
Final Words
Rancher extends the functionality of Kubernetes, even on distributions of Kubernetes that are not Rancher. Those extensions are beyond the scope of this article. At the end of this article though you have a single node Rancher management tool that can manage multiple clusters. We did so with RancherOS. Should you want to do this in production it is recommended to have a “management” Kubernetes cluster to make rancher highly available and use a certificate truted by Kubernetes, from the trusted CA cert.
When shutting down this lab, I saw that the kube-node1/2 ran out of memory and I had to increase them to 1GB as well for future boots to help avoid this.
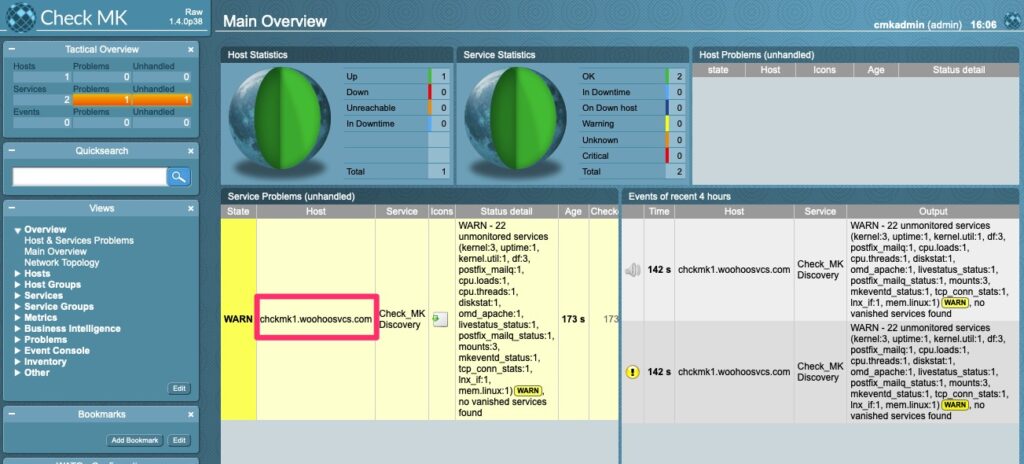
The purpose of this guide is to show the strength and flexibility of CheckMK’s distributed monitoring. As you add hosts and services, the requirements can grow. It can be easy to get in the rut of adding more CPU and RAM until you have a monstrosity of a server that you cannot expand anymore.
Centrally monitoring all sites may not even work. The central CheckMK server may not have access to all of the remote devices.
Pre-requisites and Installation
To start off, we will need another CheckMK instance. If you do not already have one, check out the Introduction to CheckMK guide. Once you have CheckMK installed and a new unique site setup, the rest is trivial
Distributed monitoring also involves the slave listening on TCP/6557 so we need to open that up
[root@chckmk2 ~]# firewall-cmd --zone=public --add-port=6557/tcp --permanent
[root@chckmk2 ~]# firewall-cmd --reload
[root@chckmk2 ~]# su - second
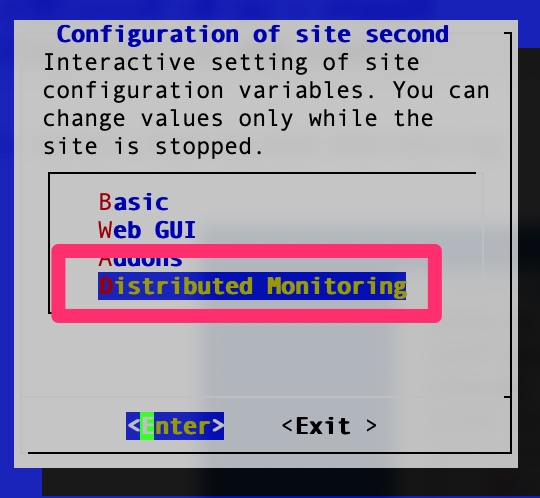
OMD[second]:~$ omd config
We then enable distributed monitoring and enable livestatus
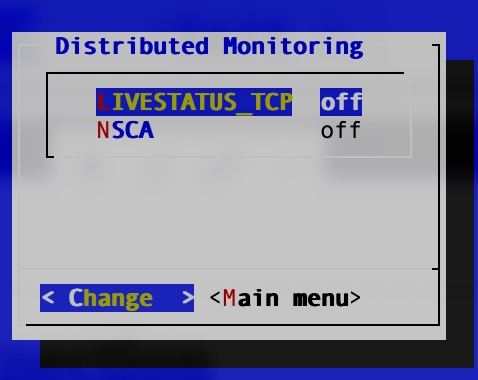
Select “Distributed Monitoring”omd livestatus
Enable livestatus which will listen on port 6557
Configure Connection
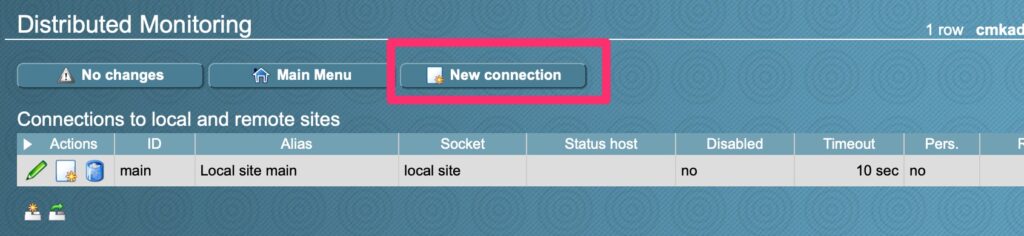
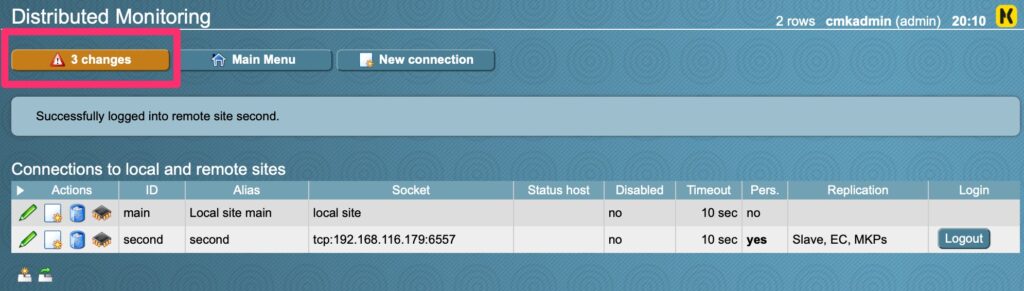
From the main site, in our series http://chckmk1.woohoosvcs.com/main navigate to Distributed Monitoring
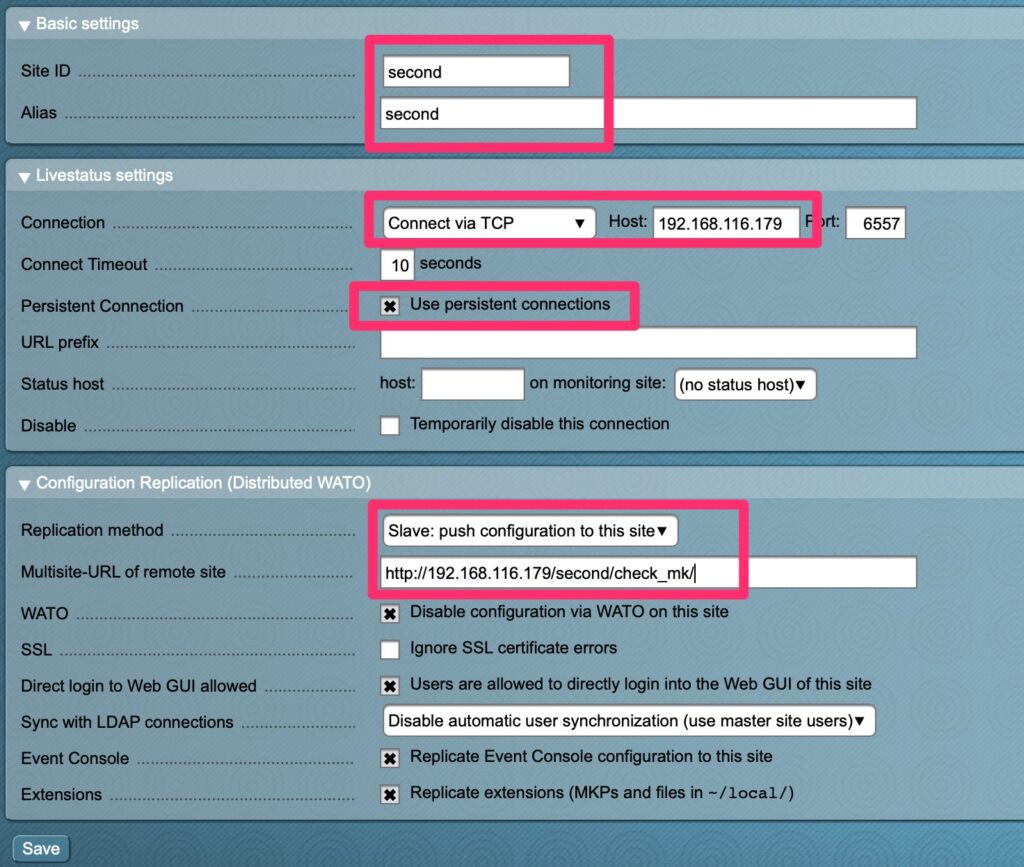
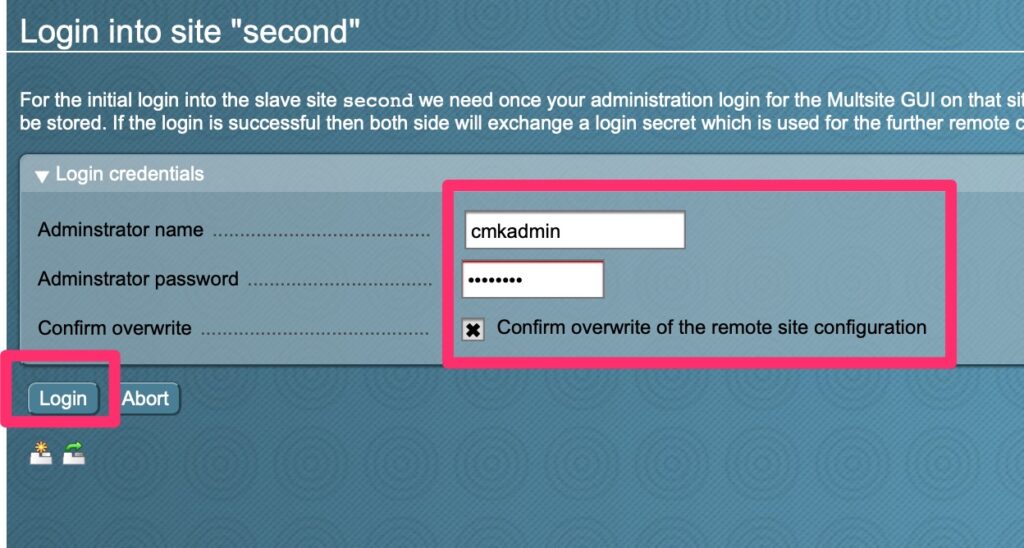
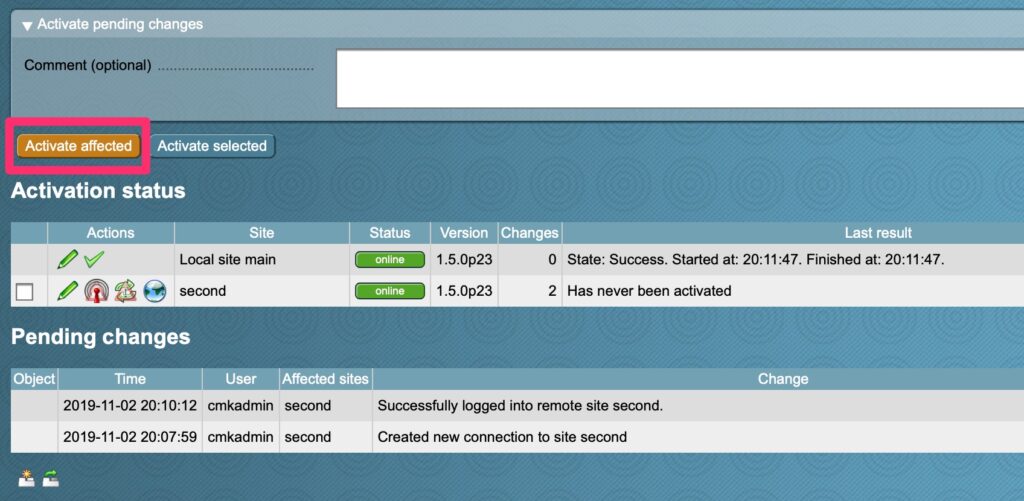
Distributed MonitoringNew ConnectionFill out the appropriate options. Select the credentials that have access to login to the second site.Login again!Save changesActivate!
Use Connection
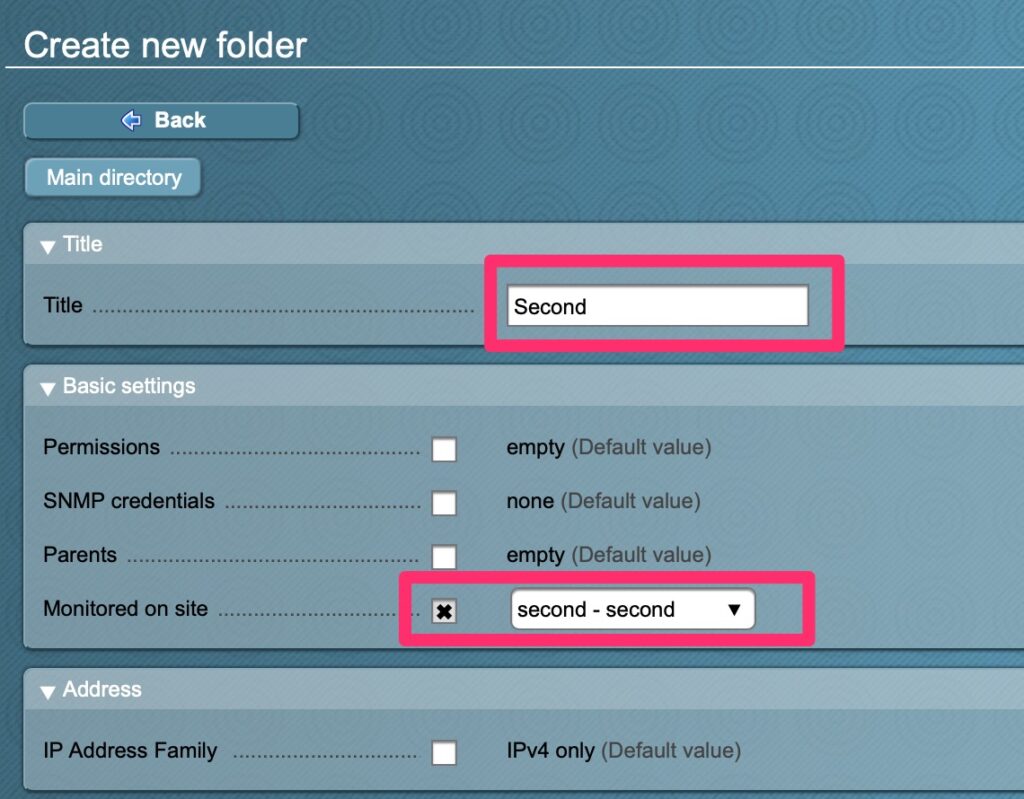
Now that we have the connection, how do we actually use it? One of the easiest and likely ways is to have a folder configured just with that monitoring site
Create a folder with a monitored site
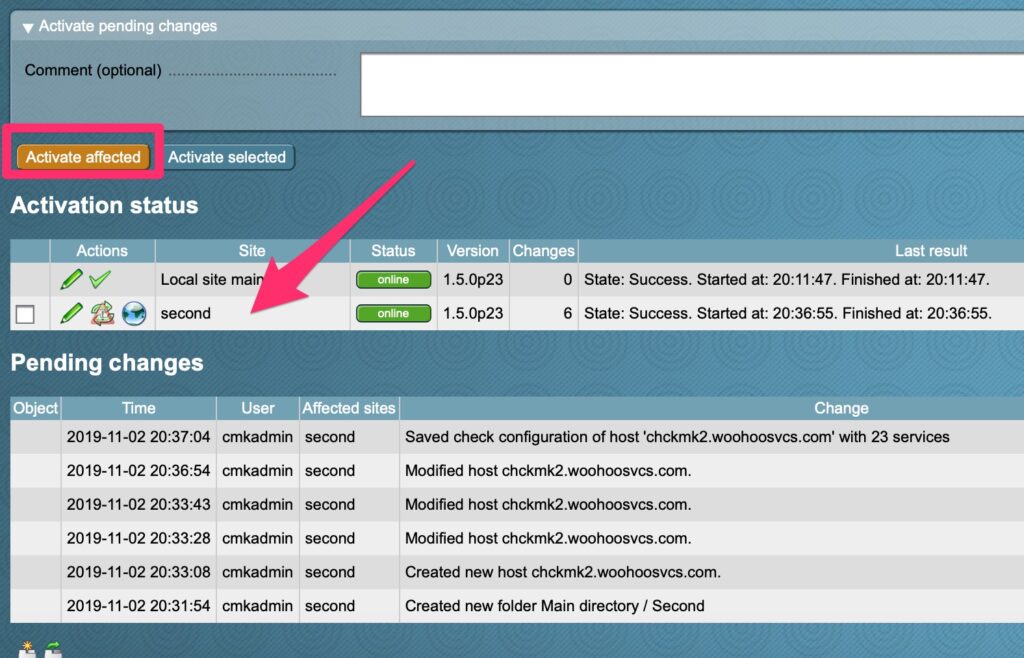
Next I added a host and put it in this new folder. Here you can see CheckMK is smart enough to know only the “second” site needs to be reloaded due to the changes that only affect it.
Activate second site changes
Final Words
This article was mostly pictures but hopefully the point comes across. That point is how flexible and easy it is to setup distributed monitoring via CheckMK.
In this article we will discuss the upgrade process using OMD. We will also go over the “werks” or changes and incompatibilities in the versions after upgrading.
If you have a fully functional environment such as one installed per Introduction to CheckMK – this should be fairly straight forward.
Prerequisites
CheckMK 1.5 RPM – We downloaded this in the previous article
Wait, what just happened? Was that it? Did it just get upgraded? Yes and no. CheckMK 1.5 was installed but our instance is not upgraded to it.
[root@chckmk1 ~]# omd sites
SITE VERSION COMMENTS
main 1.4.0p38.cre
[root@chckmk1 ~]# omd versions
1.4.0p38.cre
1.5.0p23.cre (default)
Each omd instance runs as the user so we will su to main to run commands for that instance
[root@chckmk1 ~]# su - main
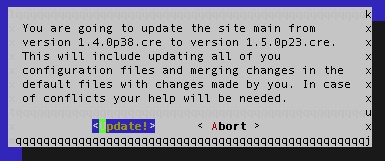
OMD[main]:~$ omd update
Please completely stop 'main' before updating it.
# Yes that's a great idea!
OMD[main]:~$ omd stop
OMD[main]:~$ omd update
“omd update”
OMD[main]:~$ omd version
OMD - Open Monitoring Distribution Version 1.5.0p23.cre
OMD[main]:~$ omd start
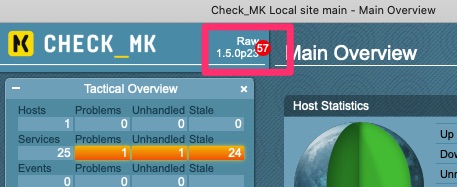
Version 1.5.0p23 with “57”
Are we there yet?
We most definitely are. We are on 1.5.0p23 and that went fairly well. But what is the “57”.
We can click on the 57 and there are 57 incompatible “werks” that we should be aware of. Many times these are non issues. Other times it is certain metrics that have gone away or configurations that have changed.
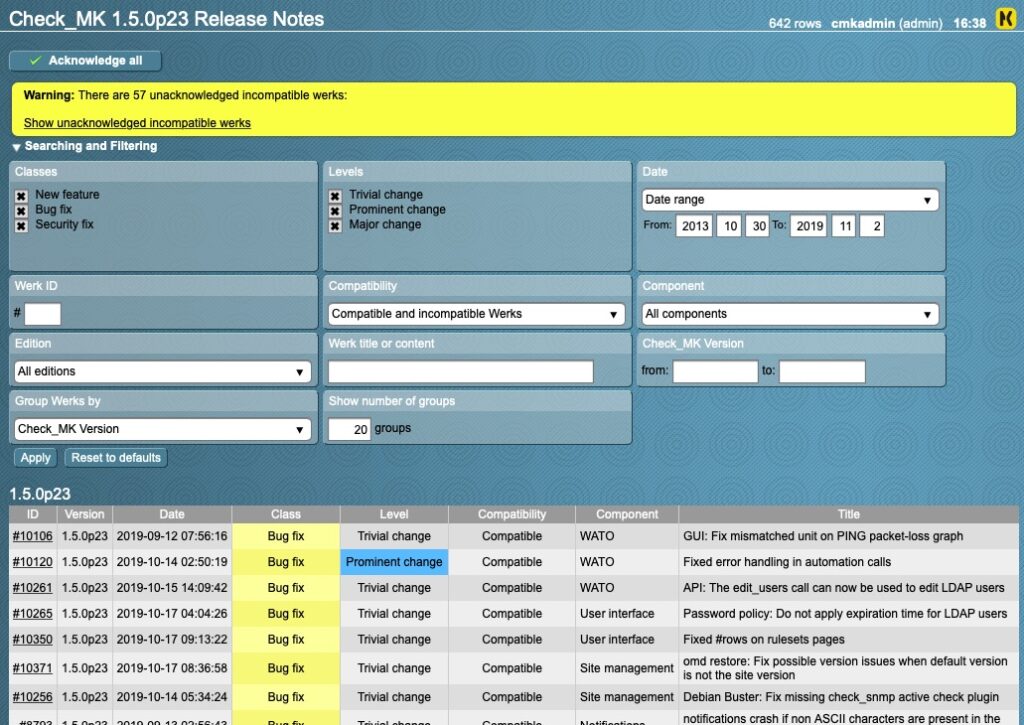
“Werks” AKA Release Notes
This is a huge help when upgrading. Instead of having to dig through text file release notes to see what major changes happened, we have werks! You can see any incompatible changes here and drilling into them will give you details on what to do. Once you have addressed it, you can acknowledge the werk.
Click on the “Show unacknowledged incompatible werks”
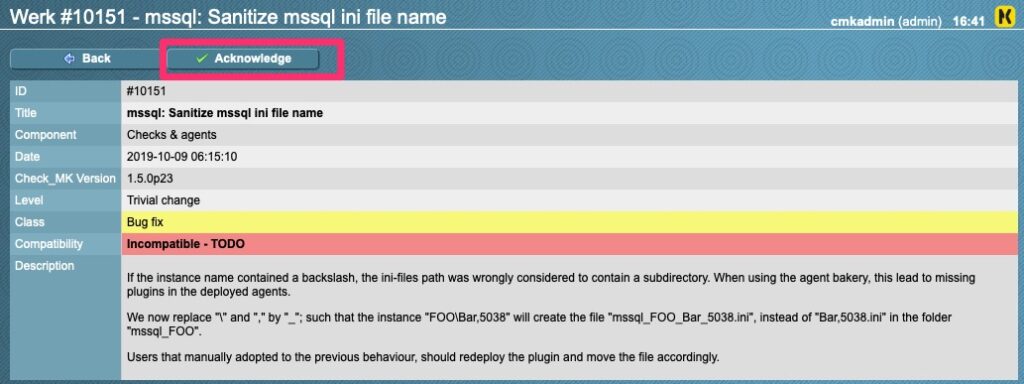
Incompatible werk. Address and acknowledge
As we can see here, there is a clear description of what changed. Once we have addressed, you can acknowledge and the 57 will decrement to 56.
You also have the option on the release notes page to “acknowledge all” if you really do not care to work through the werks. for this lab I have gone through this before and I will just acknowledge all.
If you have a large deployment, most of your time will be spent going through the werks and addressing. With that said, going from 1.4 to 1.5 has been a breeze. 1.2.8 to 1.4 was a bit rougher with more incompatible werks that caused issues.
Rollback
The power of OMD lets rollbacks come fairly easy. OMD does not care if an “upgrade” is going forward or backwards. The only issues you may have is if you made a config change only compatible or implemented in 1.5. In that case, 1.4 may have issues with it. Otherwise the rollback is the same as the upgrade. 1) stop the site 2) omd update
Final Words
Now we have a fairly up to date CheckMK. Try doing the same to 1.6.0? For my production deploys I usually wait for a few revisions and 1.6.0 is still very early for my tastes.
The purpose of this guide is to provide a high level overview of CheckMK. CheckMK is a great monitoring tool that has progressed greatly over the years. I have heavily depended on it for at least 3 years now.
Background
I came across CheckMK on a project that required a shot gun replacement of the current monitoring solution. A few solutions were vetted and Nagios was attempted. Unfortunately, the time to tweak and tune it was not compatible with the project timelines.
About CheckMK
CheckMK is an ecosystem that original was built around nagios. Many of the components of Nagios exist. Mathias Kettner is the founder of CheckMK.
There are quite a few editions but the scope of this is for the “Raw” edition. This is essentially the free unlimited tier.
Installation
Enough of the background, let’s get down to the technical installation
Requirements
For the purposes of this installation, we will be using a vanilla “minimal” install of CentOS 7.0. CentOS 7 is the latest supported version CheckMK supports. The VM will have 1 core, 1GB RAM and 8GB HDD. We will first be installing 1.4.0 so that the upgrade process can be shown.
curl -O https://checkmk.com/support/1.4.0p38/check-mk-raw-1.4.0p38-el7-85.x86_64.rpm
curl -O https://checkmk.com/support/1.5.0p23/check-mk-raw-1.5.0p23-el7-38.x86_64.rpm
# Always good to update first!
yum update
# Enable EPEL package repo
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
# Then attempt to install
yum install check-mk-raw-1.4.0p38-el7-85.x86_64.rpm
Ok, great, ran through all of that. What’s next?
Configuration
Open Monitoring Distribution
CheckMK builds upon a framework called Open Monitoring Distribution (OMD). You may be asking, why the complexity? OMD makes upgrades quite useful and can allow you to run multiple versions of CheckMK on the same machine as OMD also allows multiple instances. The CheckMK rpms install this.
The first step after installing CheckMK will be to create an OMD site
# Here you can see there are no sites
[root@chckmk1 ~]# omd sites
SITE VERSION COMMENTS
# We then create a site
[root@chckmk1 ~]# omd create main
Adding /opt/omd/sites/main/tmp to /etc/fstab.
Creating temporary filesystem /omd/sites/main/tmp...OK
Restarting Apache...OK
Created new site main with version 1.4.0p38.cre.
The site can be started with omd start main.
The default web UI is available at http://chckmk1.woohoosvcs.com/main/
The admin user for the web applications is cmkadmin with password: OkWZHNQr
(It can be changed with 'htpasswd -m ~/etc/htpasswd cmkadmin' as site user.
)
Please do a su - main for administration of this site.
[root@chckmk1 ~]# omd sites
SITE VERSION COMMENTS
main 1.4.0p38.cre default version
[root@chckmk1 ~]# omd start main
Starting mkeventd...OK
Starting rrdcached...OK
Starting npcd...OK
Starting nagios...2019-11-02 15:43:45 [6] updating log file index
2019-11-02 15:43:45 [6] updating log file index
OK
Starting dedicated Apache for site main...OK
Initializing Crontab...OK
# Open port 80 with firewalld
[root@chckmk1 ~]# firewall-cmd --zone=public --add-service=http --permanent
success
[root@chckmk1 ~]# firewall-cmd --reload
# Set SELINUX
setsebool -P httpd_can_network_connect 1
If everything went well, you should be able to browse to the IP or URL and get a login page.
CheckMK 1.4.0 Login Page
It is really that simple. You now have a working CheckMK instance ready to be configured.
CheckMK Main Page
Configuring CheckMK Application
Now that we have a working instance and want to actually monitor something, why not the CheckMK server itself? There are a few options for this. You can use SNMP, CheckMK Agent or both. We will go over installing and configuring the agent.
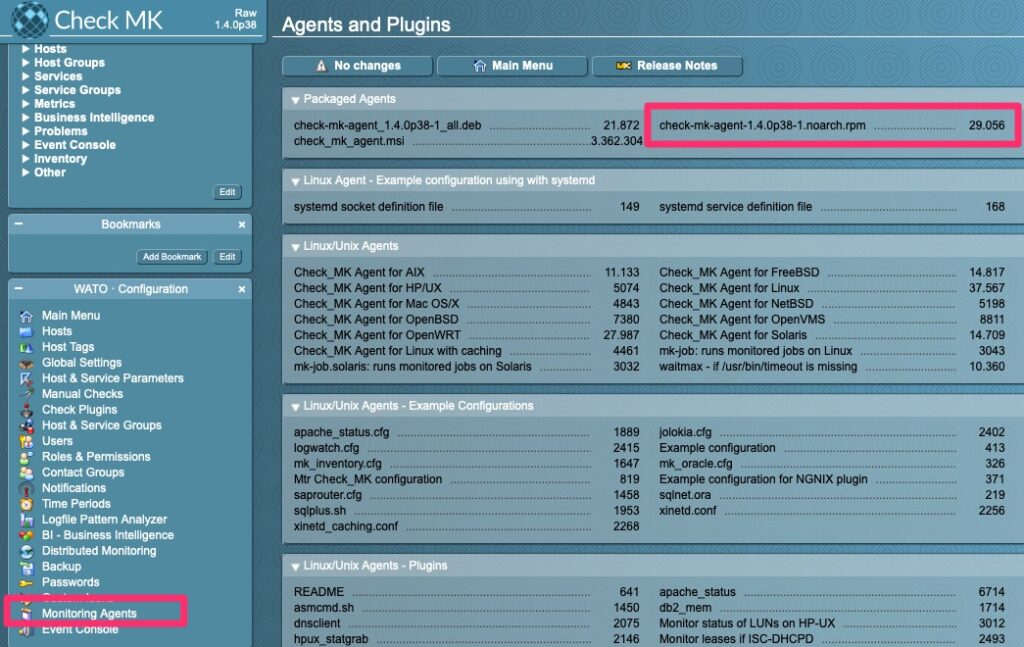
Installing the CheckMK Agent
The agent requires xinetd as it essentially ties a script (the agent) to a socket/tcp port (6556). We will put the agent directly on the checkmk server.
The agents can be found in the “Monitoring Agents” section. For RPM based distributions it is easy to just install the RPM.
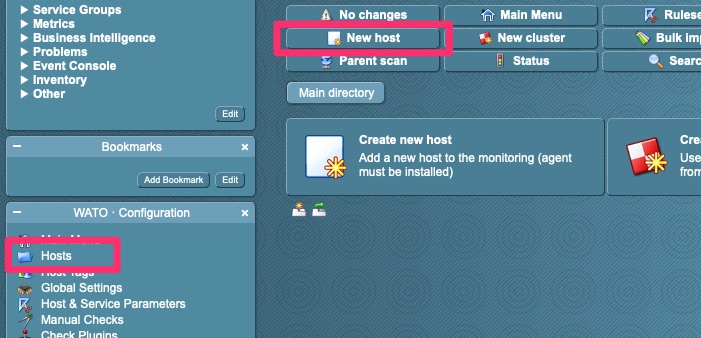
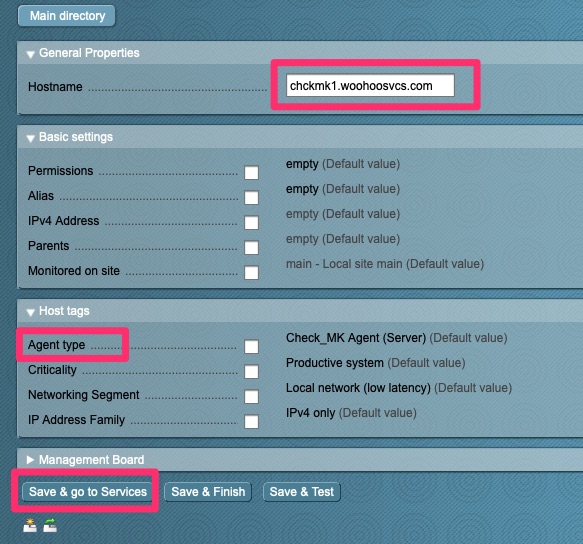
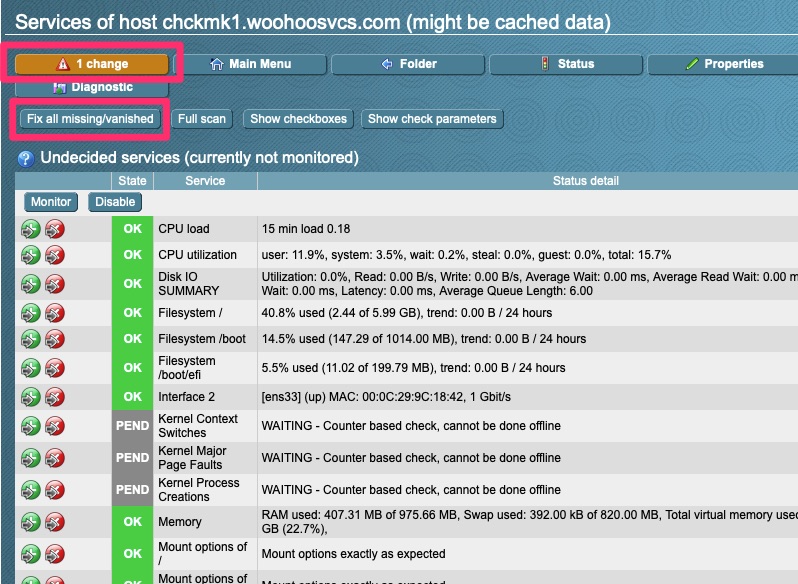
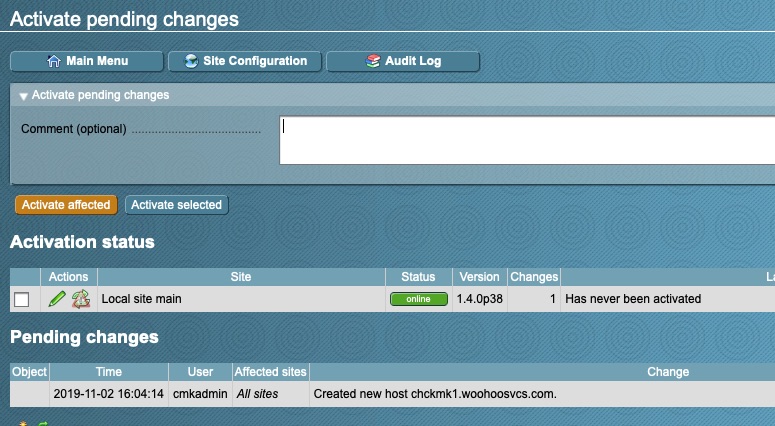
Go to “Hosts” and then “New host”Enter the Hostname or IP. The agent type defaults to Check_MK Agent but I wanted to point it out. You then want to “Save & go to Services”.This screen shows all of the services it can monitor. We want to “Fix all missing/vanished” and then save “1 change” which should after this actually change to save “2 changes”.At this point we need to activate those changes. This typically requires a reload of Nagios which the activation does.But wait, what am I seeing now and why are those hosts stale?Here we go, some activity!
At this point, we added a host and added some metrics to it. It ran through a discovery and found some more. Many times this happens. This is because some checks run asynchronously in the background. The first time you check a host, it does not return all of the services. On the second run they show up. From here you can go through similar steps to click on the host and acknowledge the new services.
In this case I simply forgot to follow my own instructions and click the “fix button”. Likely more services would have shown up later but not as many in the screenshot.
Other Configurations
Just because we have a monitoring system in place does not mean it is fully configured. We still have notifications, alert levels and many other tuning. Those are out of scope of this document but I will likely generate them going forward.
Final Words
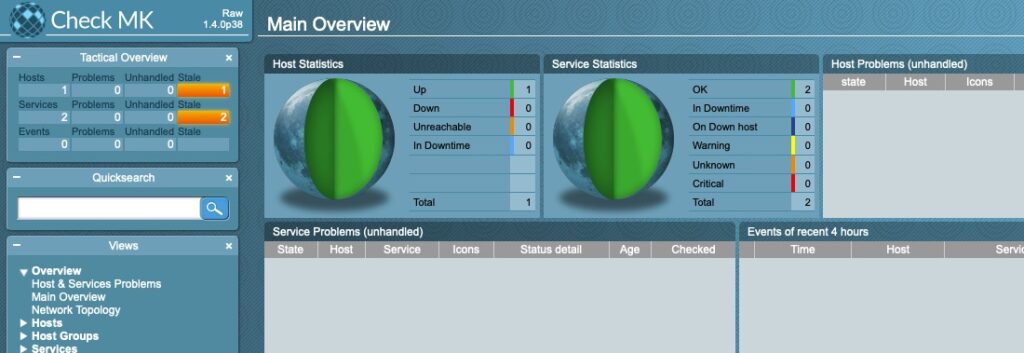
We stood up a Check_MK server from scratch and are monitoring one host. At the beginning of the article I discussed upgrading. I will follow up with another article on upgrading. The process is fairly simple but there
With all the pre-requisites met, including SSL, flannel is fairly simple to install and configure. Where it goes wrong is if some of those pre-requisites have not been met or are misconfigured. You will star to find that out in this step.
We will be running flannel in a docker image, even on the master versus a standalone which is much easier to manage.
Why Do We Need Flannel Or An Overlay?
Without flannel, each node has the same IP range associated with docker. We could change this and manage it ourselves. We would then need to setup firewall rules and routing table entries to handle this. Then we also need to keep up with ip allocations.
Flannel does all of this for us. It does so with a minimal amount of effort.
Staging for Flannel
Config
We need to update /etc/kubernetes/controller-manager again and add
I always prefer to download my yaml files so I can review and replay as necessary. Per their documentation I am just going to curl the URL and then apply it
On each node we need to add the following the the /etc/kubernetes/kubelet config and then restart kubelet
KUBELET_ARGS="--network-plugin=cni"
Firewall
Since flannel is an overlay, it overlays over the existing network and we need to open UDP/8285 per their doc. Therefore we need to put this in iptables on each host
# This line for VXLAN
-A INPUT -p udp -m udp --dport 8472 -j ACCEPT
# This line for UDP
-A INPUT -p udp -m udp --dport 8285 -j ACCEPT
Fire it up!
Now we are ready to apply and let it all spin up!
root@kube-master [ ~/kube ]# curl -O https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
root@kube-master [ ~/kube ]# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
If all is well at this point, it should be chewing through CPU and disk and in a minute or two the pods are deployed!
root@kube-master [ ~/kube ]# kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-amd64-7dqd4 1/1 Running 17 138m
kube-flannel-ds-amd64-hs6c7 1/1 Running 1 138m
kube-flannel-ds-amd64-txz9g 1/1 Running 18 139m
On each node you should see a “flannel” interface now too.
root@kube-master [ ~/kube ]# ifconfig -a | grep flannel
flannel.1 Link encap:Ethernet HWaddr 1a:f8:1a:65:2f:75
Troubleshooting Flannel
From the “RESTARTS” section you can see some of them had some issues. What kind of blog would this be if I didn’t walk you through some troubleshooting steps?
I knew that the successful one was the master so it was likely a connectivity issue. Testing “curl -v https://10.254.0.1” passed on the master but failed on the nodes. By pass, I mean it made a connection but complained about the TLS certificate (which is fine). The nodes, however, indicated some sort of connectivity issue or firewall issue. So I tried the back end service member https://192.168.116.174:6443 and same symptoms. I would have expected Kubernetes to open up this port but it didn’t so I added it to iptables and updated my own documentation.
Some other good commands are “kubectl logs <resource>” such as
root@kube-master [ ~/kube ]# kubectl logs pod/kube-flannel-ds-amd64-txz9g --namespace=kube-system
I1031 18:47:14.419895 1 main.go:514] Determining IP address of default interface
I1031 18:47:14.420829 1 main.go:527] Using interface with name eth0 and address 192.168.116.175
I1031 18:47:14.421008 1 main.go:544] Defaulting external address to interface address (192.168.116.175)
I1031 18:47:14.612398 1 kube.go:126] Waiting 10m0s for node controller to sync
I1031 18:47:14.612648 1 kube.go:309] Starting kube subnet manager
....
You will notice the “namespace” flag. Kubernetes can segment resources into namespaces. If you’re unsure of which namespace something exists in, you can use “–all-namespaces”
Final Words
Now we have a robust network topology where pods can have unique IP ranges and communicate to pods on other nodes.
Next we will be talking about Kubernetes Dashboard and how to load it. The CLI is not for everyone and the dashboard helps put things into perspective.
Picking up where we left off in the Initializing Kubernetes article, we will now be setting up certificates! This will be closely following the Kubernetes “Certificates” article. Specifically using OpenSSL as easyrsa has some dependency issues with Photon.
OpenSSL
Generating Files
We’ll be running the following commands and I keep them in /root/kube/certs. They won’t remain there but its a good staging area that needs to be cleaned up or secured so we don’t have keys laying around.
In my environment the MASTER_IP is 192.168.116.174 and the cluster IP is usually a default but we can get it by running kubectl
root@kube-master [ ~/kube ]# kubectl get services kubernetes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 60m
[ req ]
default_bits = 2048
prompt = no
default_md = sha256
req_extensions = req_ext
distinguished_name = dn
[ dn ]
C = US
ST = Texas
L = Katy
O = Woohoo Services
OU = IT
CN = 192.168.116.174
[ req_ext ]
subjectAltName = @alt_names
[ alt_names ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster
DNS.5 = kubernetes.default.svc.cluster.local
IP.1 = 192.168.116.174
IP.2 = 10.254.0.1
[ v3_ext ]
authorityKeyIdentifier=keyid,issuer:always
basicConstraints=CA:FALSE
keyUsage=keyEncipherment,dataEncipherment
extendedKeyUsage=serverAuth,clientAuth
subjectAltName=@alt_names
We need to copy the ca.crt to /etc/ssl/certs/kube-ca.pem on each node and then install the package “openssl-c_rehash” as I found here. Photon is very minimalistic so you will find you keep having to add packages for things you take for granted.
tdnf install openssl-c_rehash
c_rehash
Doing //etc/ssl/certs
link 3513523f.pem => 3513523f.0
link 76faf6c0.pem => 76faf6c0.0
link 68dd7389.pem => 68dd7389.0
link e2799e36.pem => e2799e36.0
.....
link kube-ca.pem => 8e7edafa.0
Final Words
At this point, you have a Kubernetes cluster setup with some basic security. Not very exciting, at least in terms of seeing results but the next article should be meaningful to show how to setup flannel.
In my previous article Intro To Kubernetes, we walked through installing dependencies and setting the stage for initializing Kubernetes. At this point you should have a master and one or two nodes with the required software installed.
A Little More Configuration
Master Config Prep
We have just a little more configuration to do. On kube-master we need to change “/etc/kubenertes/apiserver” lines as follows. This allows other hosts to connect to it. If you don’t want to bind to 0.0.0.0 you could bind to the specific IP but would lose localhost binding.
# From this
KUBE_API_ADDRESS="--insecure-bind-address=127.0.0.1"
# To this
KUBE_API_ADDRESS="--address=0.0.0.0"
Create the Cluster Member Metadata
Save the following as a file, we’ll call it create_nodes.json. When standing up a cluster I like to start out with doing it on the master so I create a /root/kube and put my files in there for reference.
We can then run kubectl to create the nodes based on that json. Keep in mind this is just creating metadata
root@kube-master [ ~/kube ]# kubectl create -f /root/kube/create_nodes.json
node/kube-master created
node/kube-node1 created
node/kube-node2 created
# We also want to "taint" the master so no app workloads get scheduled.
kubectl taint nodes kube-master key=value:NoSchedule
root@kube-master [ ~/kube ]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-master NotReady <none> 88s
kube-node1 NotReady <none> 88s
kube-node2 NotReady <none> 88s
You can see they’re “NotReady” because the services have not been started. This is expected at this point.
All Machine Config Prep
This will be run on all machines, master and node. We need to edit “/etc/kubernetes/kubelet”
server: http://127.0.0.1:8080
# Should be
server: http://kube-master:8080
In /etc/kubernetes/config
KUBE_MASTER="--master=http://kube-master:8080"
Starting Services
Master
The VMware Photon Kubernetes guide we have been going by has the following snippit which I want to give credit to. Please run this on the master
for SERVICES in etcd kube-apiserver kube-controller-manager kube-scheduler kube-proxy kubelet docker; do
systemctl restart $SERVICES
systemctl enable $SERVICES
systemctl status $SERVICES
done
You can then run “netstat -an | grep 8080” to see it is listening. Particularly on 0.0.0.0 or the expected bind address.
Nodes
On the nodes we are only starting kube-proxy, kubelet and docker
for SERVICES in kube-proxy kubelet docker; do
systemctl restart $SERVICES
systemctl enable $SERVICES
systemctl status $SERVICES
done
Health Check
At this point we’ll run kubectl get nodes and see the status
root@kube-master [ ~/kube ]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
127.0.0.1 Ready <none> 23s v1.14.6
kube-master NotReady <none> 3m13s
kube-node1 NotReady <none> 3m13s
kube-node2 NotReady <none> 3m13s
Oops, we didn’t add 127.0.0.1 – I forgot to clear the hostname override in /etc/kubernetes/kubelet. Fixed that, restarted kubelet and then “kubectl delete nodes 127.0.0.1”
It does take a while for these to start showing up. The provisioning and orchestration processes are not fast but you should slowly show the version show up and then the status to Ready and here we are.
root@kube-master [ ~/kube ]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-master Ready <none> 9m42s v1.14.6
kube-node1 Ready <none> 9m42s v1.14.6
kube-node2 Ready <none> 9m42s v1.14.6
Final Words
At this point we could start some pods if we wanted but there are a few other things that should be configured for a proper bare metal(or virtual) install. Many pods are now depending on auto discovery which uses TLS. Service accounts also need and service accounts are using secrets.
For the networking we will go over flannel which will provide our networking overlay using VXLAN. This is needed so that pods running on each node have a unique and routable address space that each node can see. Right now each node has a docker interface with the same address and pods on different nodes cannot communicate with each other.
Flannel uses the TLS based auto discovery to the ClusterIP. Without hacking it too much it is just best to enable SSL/TLS Certificates and also a security best practice.
This will be part of a multi-part set of posts on Kubernetes. There are many other technical articles on this but I could not find one that got me end to end to my desired state with Kubernetes. These series of posts will help carry you through my journey at standing it up.
What This Is Not
Currently, this series is not a high level architecture overview. It does not go into detail of the various daemons and their function. I may create a separate article on this at a later date.
Why Kubenertes?
Kubernetes aka k8s, is great at provisioning resources and maintaining them for containerized workloads using Docker. Per the site’s tag line, “Production-Grade Container Orchestration”. It was developed in house by Google and shared with the public. Therefore Google Cloud’s Kubernetes offering is one of the better ones. Docker Swarm is Docker’s response to the need this fills.
Let’s Get Started!
For this series I will be using VMware Photon OS. You are more than welcome to use any distribution you wish although many of the commands may not be the same, particularly the package management commands to install software. I use VMware Fusion but any hypervisor or bare metal systems will suffice. We will be standing up 3 total nodes but you can do with 2 if resources are at a minimum.
We will also be following VMware’s Guide to installing Photon on Kubernetes with a minor tweak.
Installation
Install the OS
If you are looking to install something like Kubernetes it is assumed you are fairly familiar with installing an OS. For this we will need 3 instances of Photon. I am provisioning them with 4GB HDD, 1 core, 768 MB of RAM and removing any excess virtual hardware not needed since the machine I am running this on only has 8GB of RAM and dual core.
The machine names will be kube-master, kube-node1 and kube-node2
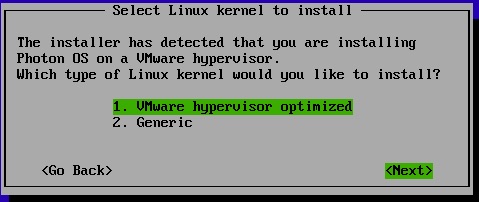
For Photon, you can pretty much accept the defaults with the kernel type being the only one you may need to think about. Photon can go on bare metal or even other hypervisors, but it does have a VMware optimized kernel with vm tools if you choose.
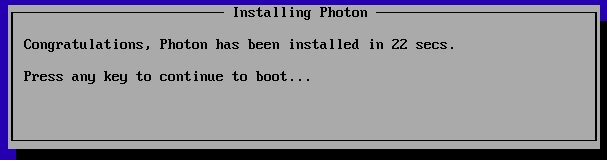
Photon is very proud of their install times, but it is nice not waiting 10-20 mins for an OS install
Login to the OS
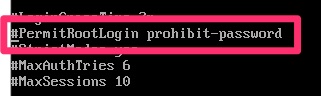
By default, most recent distributions of Linux, including Photon are locked down. You can login to root at the console but not remotely unless you use ssh keys authentication. For production workloads, I would highly recommend not using the root login and instead using another login and sudo but for the purpose of this lab we will just add my local key to root and be on our way.
I personally use ssh-copy-id which is a best practice
dwcjr@Davids-MacBook-Pro ~ % ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/Users/dwcjr/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
Password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '[email protected]'"
and check to make sure that only the key(s) you wanted were added.
Installing Kubernetes on Master and Nodes
Photon uses tdfn so its quite simple. This is also where we deviate slightly from the instructions. We will be enabling all of the node services on the master so that it can run docker images. We do not want to run actual app images but there is a particular system image we will want to run that I will get into later
On Master and Nodes run the following
tdnf install kubernetes iptables docker
# Good idea to run through updates afterwards as well
tdnf update
Preparing Hosts
Next its a good idea to have a hosts file entry since we will not be using DNS for the scope of these tutorials. These are my IPs in this case.
We then need to set /etc/kubernetes/config on all hosts to specifically update
KUBE_MASTER="--master=http://kube-master:8080"
On the master, we need to edit “/etc/systemd/scripts/ip4save” to add the following lines
-A INPUT -p tcp -m tcp --dport 8080 -j ACCEPT
-A INPUT -p tcp -m tcp --dport 6443 -j ACCEPT
-A INPUT -p tcp -m tcp --dport 10250 -j ACCEPT
#Then restart iptables. On photon it doesn't appear to save IP tables between reboots so this is how it persists.
systemctl restart iptables
On the nodes you will need to add a similar line and restart iptables but it will be
-A INPUT -p tcp -m tcp --dport 10250 -j ACCEPT
Ending Note
At this point you do not quite have anything near a functional Kubernetes cluster but this was the first part in a few. I decided to break this article at this point as some people may be able to easily get here without these instructions.
For those that made it here, my next article will link here for the initial Kubernetes Configuration