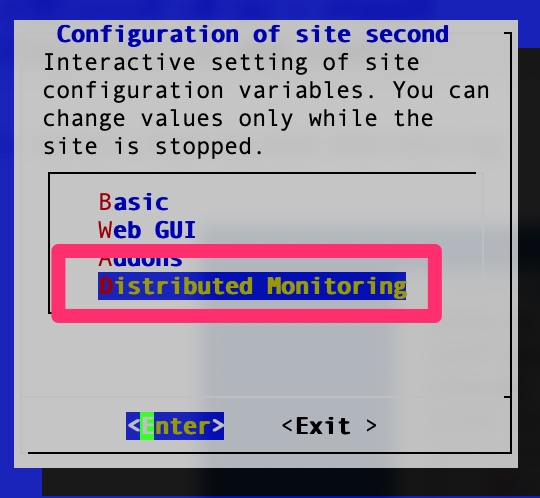
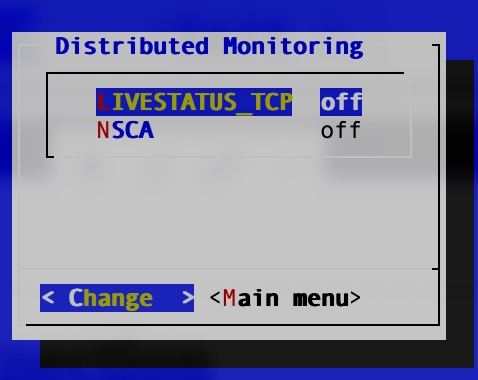
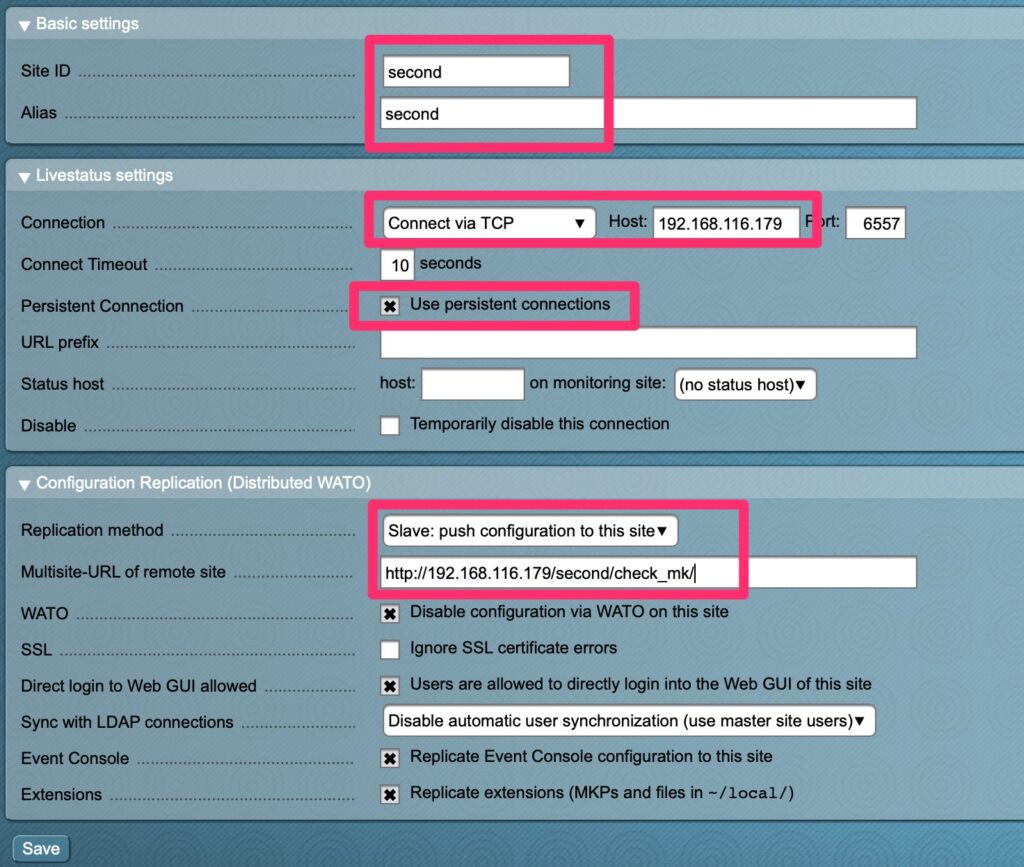
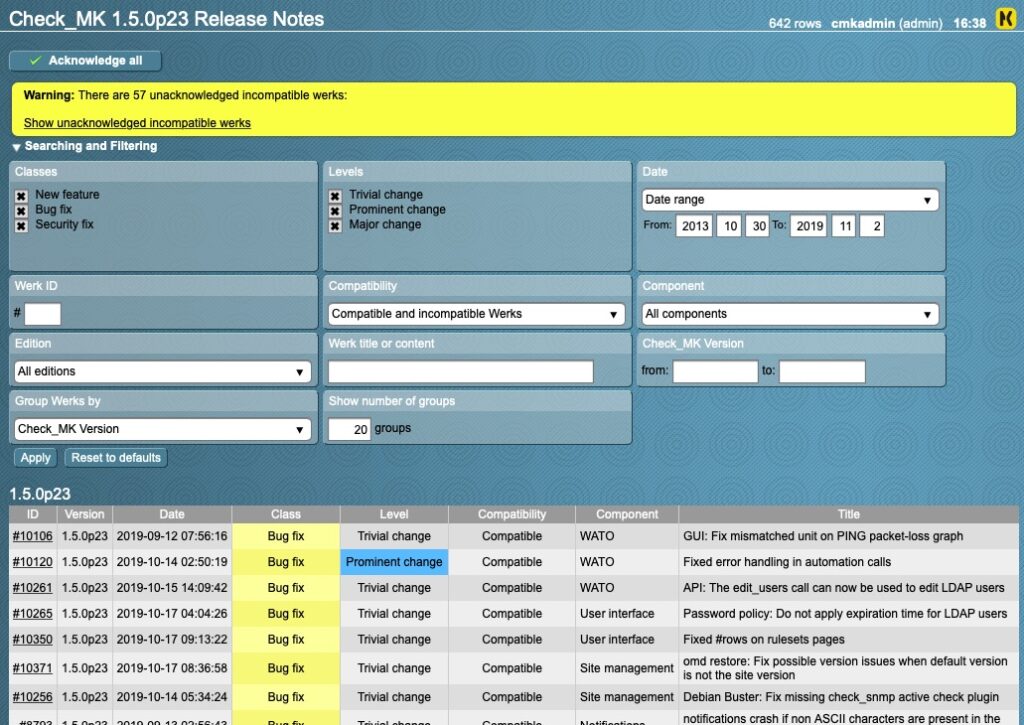
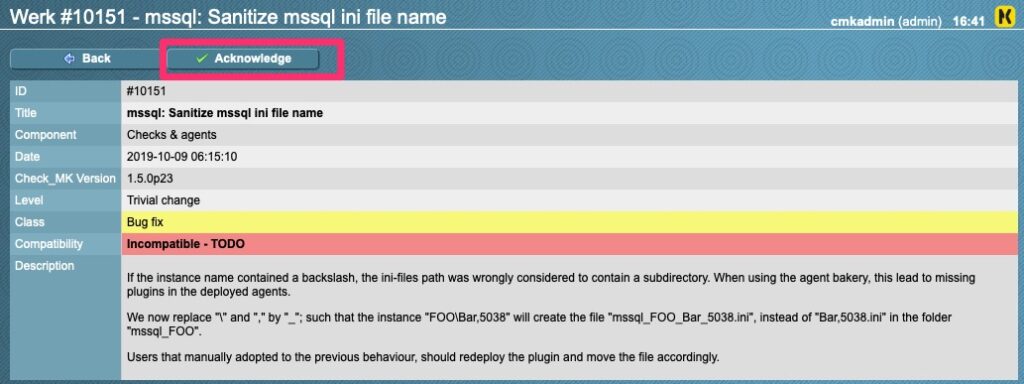
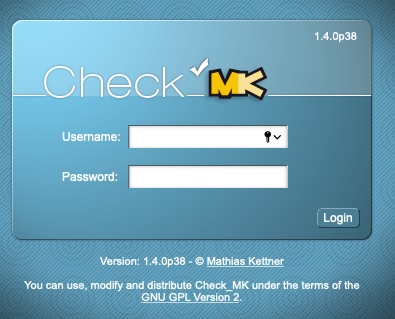
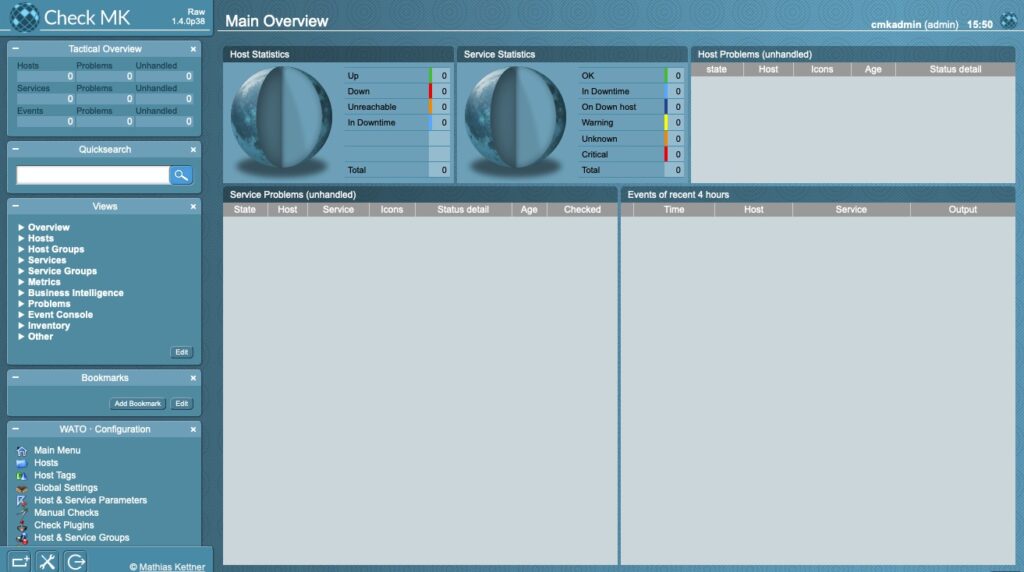
Summary
Many people in the IT space suffer from back pains at one point or another. 5-10 years ago I thought back pain was just for those that were unhealthy. Then, earlier this year, it hit me. It was pain like no other. Not just muscle pain but felt like “bone on bone” pain. For the first time, I went to a chiropractor. It helped but depending on that did not seem like the long term solution. Here is my journey and thoughts on back pain. Hopefully it can help you!
Over the Years
Over the years I have had the occasional back pain from tense muscles. It usually came from a stressful day and left a day or two later. Exercise and a good night sleep usually fixed it. Sometimes it was as simple as my body telling me it was time for new shoes! Soles of shoes can wear over time and stop providing the support needed.
Doctor Time?
That was until earlier this year I woke up one morning with some absolutely terrible back pain that caused me to go to the chiropractor. After a few sessions of adjustments and deep tissue massage, I was on my way. It was not completely gone but bearable. I kept asking what I could do differently but was repeatedly told me it was just life and to keep coming back. The chiropractor was a highly reputable one so I believed it. Perhaps he was just tired of giving people advice that they never took.
It came back again a few weeks later until I took a family stay-vacation. Some family came into town and I was off work for a week. My back pain was gone so I realized it had something to do with my work routine.
Change it up!
I decided to rotate my mattress and eventually get a new one. I replaced my shoes to see if that helped. These minor changes were making a dent but still not quite doing it. Then I started looking at my chair. It was a typical adjustable task chair but it was about 15-20 years old. My wife on the other-hand had a nice Serta executive chair she inherited from my father. I swapped chairs for 1 day and felt “cured”. It was a miracle!
The Chair!
Upon investigating chairs and doing my research on my own chair, it had a few issues. The chair was fairly old so the padding was pretty shot. It also did not have any lumbar support. That was the primary area of my back pain. The Serta chair, on the other hand, had copious amounts of lumbar support. Knowing it was my chair that was the issue, I sought out finding an economical replacement.
Chair Qualities
As I would come to find out, there were a few qualities of a chair that would help support the back and help to prevent or mitigate back pain
Lumbar Support
What is lumbar and lumbar support? The lumbar is the lower region of the back. It has a natural curve to it.
Taken from – https://www.hopkinsmedicine.org/health/conditions-and-diseases/lumbar-strain-weight-lifters-back
In chairs that do not have lumbar support (curved to match to this), we tend to press up to the back and lose that natural curve. This causes the spin to sit in a way that can cause pain over time. The reason for this is muscles are supporting the back that do not usually do so. Then over more time, we tend to hunch or change positions to more unhealthy positions
Lean Back!
No, its not just a song feating Fat Joe! The ability of a chair to tilt and allow you to lean back allows for the back of the chair to take most of the weight of your upper body off your back and place some of it on the chair. This reduces the strain on back and back muscles.
Armwrests
In terms of mitigating back pain, these are fairly terrible if you spend your day typing on a keyboard. The reason for this also goes along with design flaws in desks. Perhaps flaw is not the right word but a choice of aesthetic over function.
An ideal setup allows for your elbows to be parallel to the desk when sitting so that your arms can rest on the desk comfortably without contorting your shoulders and putting strain on them. The problem with armwrests is they typically prevent you from adjusting your chair to a proper height to allow for that. For this reason I typically remove the arm wrests completely when possible.
Some desks come with drawers under the desk, in the sitting area which cause similar issues. Your chair should be adjusted so that there is a minimal amount of space between the top of your legs and the bottom of the desk to best allow your forearms to be parallel to the desk and resting comfortably.
Adjustable Desks
An adjustable desk helps with this greatly too. Sitting all day or standing all day is bad for your posture. Sit all day and your hips get tight or tense and need to be stretched. Stand all day and your back will definitely hurt. I like the flexibility of an adjustable desk so that I can change positions every few hours.
Not everyone can afford a real adjustable desk so there are cheap “hacks” you can find that will allow you to place your keyboard and monitor on a stand that adjusts on top of your desk. IKEA has some “economical” motorized adjustable desks too for $400 USD
Other Remediations
While I did not want to see a chiropractor long term, deep tissue massage is likely a must for me on some sort of schedule and I highly recommend it.
I find that using a foam roller on my upper back helps tremendously as well as tennis ball. These work wonders to help to work out knots if you cannot get to or afford a deep tissue massage.
Please do be careful with these methods though. You can make your back problems much worse if you do them incorrectly. Many times an out of alignment back can cause these issues so I recommend doing the full foam rolling exercise but leave out your lower back.
Final Words
Sometimes resolving back pain is a matter of finding the silver bullet and changing that one thing. Other times you may have a few life circumstances that are causing it. Be persistent though and hopefully this article has given you a few different areas to investigate!